Using Chrome DevTools for SEO
This tutorial covers a few useful snippets that you can use in your daily technical SEO work, leveraging the power of modern browsers, to save time. If you already use the Network tab and the Elements tab to check for the most common issues in SEO, you might enjoy this tutorial about Snippets and the results printed in the Console.
This article is available in french as well 🇫🇷
Table of contents
Snippet #2: Find href attributes on a page 🧶 (along with their status code & anchor text)
Snippet #4: Find and compare rendered HTML canonical URL vs source HTML canonical URL
Snippet #8: Get hreflang link alternate tag found on the page
Welcome to Chrome DevTools: We are the Snippets!
Here's an intro about Chrome Snippets in DevTools, from the Chrome for Developers YouTube channel:

Pretty cool right? 😎 Now that you are familiar with the Snippets, let's see what we can do with them for SEO.
I work in a corporate environment that allows little freedom in using SEO tools, let alone browser extensions, for security reasons. So I started thinking about some of the repetitive tasks that I'd like to gain time with, while using only the browser as a tool.
Why?
Let's start with a few pointers; this tutorial is for you if you are curious, are already using the Elements and Network and other tabs in DevTools and ...
... you cannot use / don't want to use ready made browser extensions (for any given reason).
... you are OK with the results being printed in your browser's 'console'. Of course you could modify any of the below snippets to make them act like bookmarklets and more (maybe have an export feature?)
⚠️ Worth noting that you get a maximum of 999 results, and all is case sensitive.
Snippet #1: Check URLs on an XML Sitemap (along with their canonical, meta robots tag, status code & disallow directive)
🔬 Scenario: You are working on an XML Sitemap. You've identified that some of the pages included in the XML Sitemap...
are not indexable, and want to remove them from the XML Sitemap
or some pages are disallowed from being crawled in the robots.txt file for a good reason, and you'd like to keep them as such
or you are simply working on removing some unuseful page from the XML Sitemap
So you've asked your team to make the changes and you want to verify the implementation, on staging and then on the live server.
Here's a snippet that looks up the 'terms' that you want check for in the <loc> URLs, checks them against the robots.txt file on the root (to see if they are disallowed from being crawled), checks their status code since you don't want anything but 200 status codes in your XML Sitemap, checks their <title> and <h1> tag elements, checks for <meta name="robots"> tag element, and checks for the canonical URLs of each the URLs you want to verify.
// Async function to check if URL is allowed by robots.txt
const isAllowedByRobotsTxt = async (url) => {
const robotsUrl = `${new URL(url).origin}/robots.txt`;
try {
const content = await (await fetch(robotsUrl)).text();
const userAgentRules = content.split('User-agent: \*');
if (userAgentRules.length < 2) return true;
const rules = userAgentRules\[1].split('User-agent:')\[0];
const disallowedPaths = rules.split('\n')
.filter(line => line.trim().startsWith('Disallow:'))
.map(line => line.split('Disallow:')\[1].trim());
return !disallowedPaths.some(path => new URL(url).pathname.startsWith(path));
} catch (e) {
return true; // Assume allowed if there's an error fetching or parsing robots.txt
}
};
// Initialize variables
let ret = \[];
let fetchPromises = \[]; // To keep track of fetch promises
// Array of keywords to search for in the URLs
const keywords = \['terms', 'tum', '404', 'cookie'];
// Now proceed with the main logic
document.querySelectorAll('loc').forEach((item) => {
const url = item.textContent;
// Check if the URL contains any of the keywords
if (keywords.some(keyword => url.includes(keyword))) {
const fetchPromise = fetch(url)
.then(response => {
if (!response.ok) {
throw new Error(`HTTP error ${response.status}`);
}
return { response, text: response.text() };
})
.then(({ response, text }) => Promise.all(\[response, text]))
.then(async (\[response, html]) => {
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
const h1Texts = Array.from(doc.querySelectorAll('h1')).map(h1 => h1.textContent).join(', ');
// Check for robots meta tag in <head>
const metaRobots = doc.querySelector('head meta[name="robots"]');
const metaContent = metaRobots ? metaRobots.getAttribute('content') : 'N/A';
// Check for canonical URL
const canonicalLink = doc.querySelector('head link[rel="canonical"]');
const canonicalUrl = canonicalLink ? canonicalLink.getAttribute('href') : 'N/A';
// Check if the URL is allowed by robots.txt
const isAllowed = await isAllowedByRobotsTxt(url);
ret.push({
"URL": url,
"Canonical URL": canonicalUrl,
"Status Code": response.status,
"Status Text": response.statusText,
"Title": doc.title,
"Robots Meta": metaContent,
"h1 Texts": h1Texts,
"Disallowed by Robots.txt": isAllowed ? "No" : "Yes"
});
})
.catch(error => {
ret.push({
"URL": url,
"Canonical URL": "N/A",
"Status Code": "Error",
"Status Text": error.message,
"Title": "N/A",
"Robots Meta": "N/A",
"h1 Texts": "N/A",
"Disallowed by Robots.txt": "Check Failed"
});
});
fetchPromises.push(fetchPromise);
}
});
// Wait for all fetch calls to complete and then print the table
Promise.all(fetchPromises).then(() => {
console.table(ret);
});In this example, I'm asking the browser to check for URLs in <loc> on the XML Sitemap doc that contain the word 'terms' or '404' or 'tum' or 'cookie'; you can change those of course to find your desired 'term' in the URLs.
You would typically copy paste this and save it in your browser's snippets, and then visit an XML Sitemap that you want to verify, and then run the snippet. Here's an example:
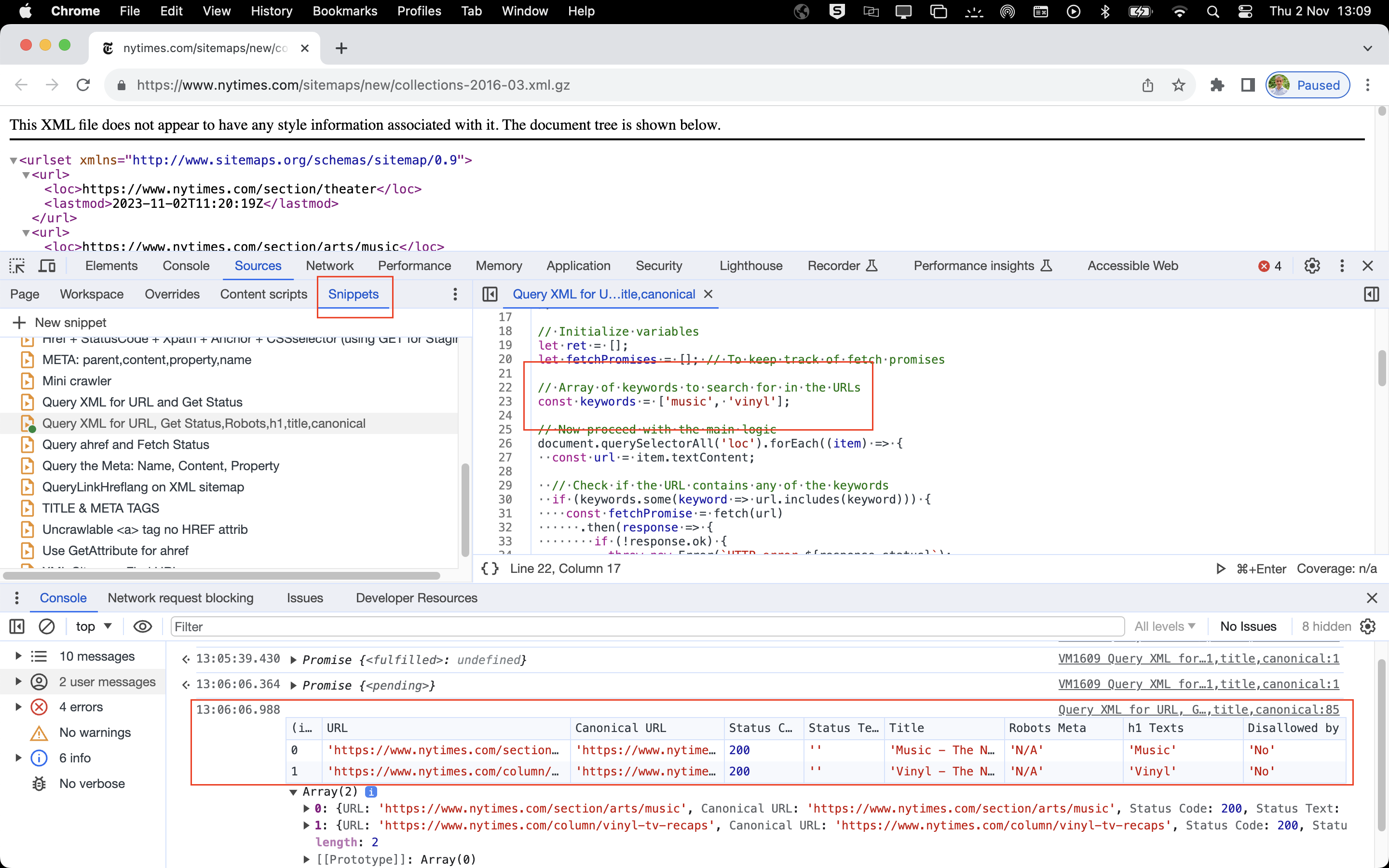
In this example above, we're checking if any of the URLs submitted in the XML Sitemap include the words 'music' or 'vinyl'. And it works pretty fast, depending on the number of queries you are requesting.
The above also works in a staging environment, but obviously the robots.txt result becomes obsolete: the staging is blocked from crawling via a login regardless of the robots.txt directives in my case.
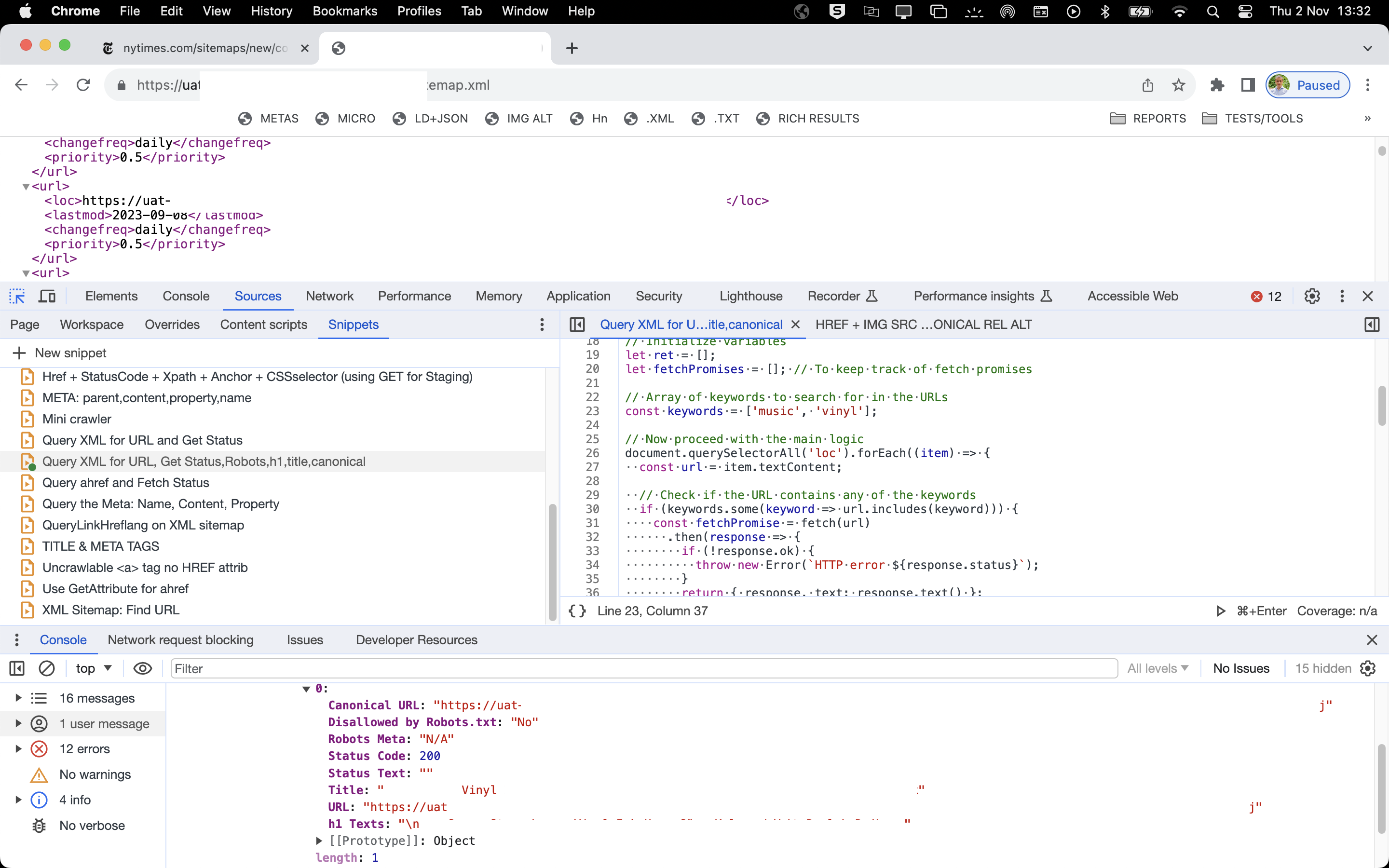
The white space you see in due to the fact that I removed the URLs and sensitive information parts from the above screenshot on staging.
🧐 Conclusion:
The script features an asynchronous function, isAllowedByRobotsTxt, which verifies whether a given URL is permitted for crawling as dictated by the website's robots.txt file.
We then initiate a series of fetch requests to URLs that contain specific 'keywords', collecting data such as HTTP status, canonical URL, and <meta name="robots"> tags, allowing you to determine its usefulness in the XML Sitemap.
Finally, the data gathered is consolidated and displayed in a table in your browser's console. This bit of javascript works for Chrome and Firefox, I'm pretty sure you can use it on any modern browser.
Now I don't have to go through extensive checks and certainly not run a new crawl for every change request that I want to verify.
ℹ️ Useful tip:
I keep a bookmarklet to quickly visit the XML Sitemaps of sites I frequently visit.
By now you already know that a bookmarklet is a small piece of JavaScript code that can be saved as a bookmark in your web browser. The javascript executes a small script - much like an extension - when you click on it.
In this case, the below bookmarklet will open the sitemap of the current website you are viewing, provided the URL structure is 'domain .com /sitemap.xml'. You can obviously adjust it to your liking. When combined, window.location.origin + '/sitemap.xml' generates a URL that points to the sitemap of the website you are currently on. If the sitemap location is, let's say, under the folder /sitemap/, then you could adjust it to become window.location.origin + '/sitemap/sitemap.xml' .
javascript:(function(){window.open(window.location.origin + '/sitemap.xml');})();Step by step:
Right-click on your bookmarks bar in your web browser.
Select "Add page", "New bookmark", or a similar option (the exact wording will depend on your browser).
In the Name field, enter a name for the bookmarklet, like "Open Sitemap".
In the URL field, paste the JavaScript code given:
javascript:(function(){window.open(window.location.origin + '/sitemap.xml');})();Save the bookmarklet. Now, whenever you want to open the sitemap of a particular website, simply click on this bookmarklet while you are on that website.
You can do a lot of useful things with bookmarks, that will save you a lot of time. I also apply the same bookmarklet to quickly access the robots.txt file: javascript:(function(){window.open(window.location.origin + '/robots.txt');})();
These bookmarks are a life saviour when you deal with hundreds of websites everyday.
Snippet #2: Find href attributes on a page 🧶 (along with their status code & anchor text)
🔬 Scenario: One of the recurring tasks that we deal with on daily basis, is finding and verifying internal links - broken ones or else.
This snippet does exactly that: you've requested for some broken URLs to be fixed, now you need to verify that it is actually fixed. You typically need the location of the link (Xpath or CSSselector), the status code of the target URL and the anchor text.
// Function to get XPath for an element
async function getXPathForElement(element) {
let xpath = '';
for (; element && element.nodeType === 1; element = element.parentNode) {
const id = element.getAttribute('id');
if (id) {
xpath =
// Function to get CSS selector for an element
function getCSSSelectorForElement(element) {
if (element.id) {
return
// Function to get status code for a URL
async function getStatusCode(url) {
try {
const response = await fetch(url, {
method: 'GET',
credentials: 'include' // Include credentials like cookies in the request
});
return response.status;
} catch (error) {
return 'Error: Unable to fetch';
}
}
// Main function
(async () => {
let ret = [];
const links = document.querySelectorAll('a[href]');
for (const item of links) {
if (item.href.includes('service')) {
const statusCode = await getStatusCode(item.href);
ret.push({
"URL": item.href,
"Anchor Text": item.innerText,
"XPath": await getXPathForElement(item),
"CSS Selector": getCSSSelectorForElement(item),
"Status Code": statusCode
});
}
}
console.table(ret);
})();With this example, I'm looking for the href attribute that includes the word 'service'.
Instead of running a new crawl, and since I know what I'm looking for, I could easily run this snippet - even in staging environments - to look up what I believe has been fixed, and get the result in the browser's console in less than a second.
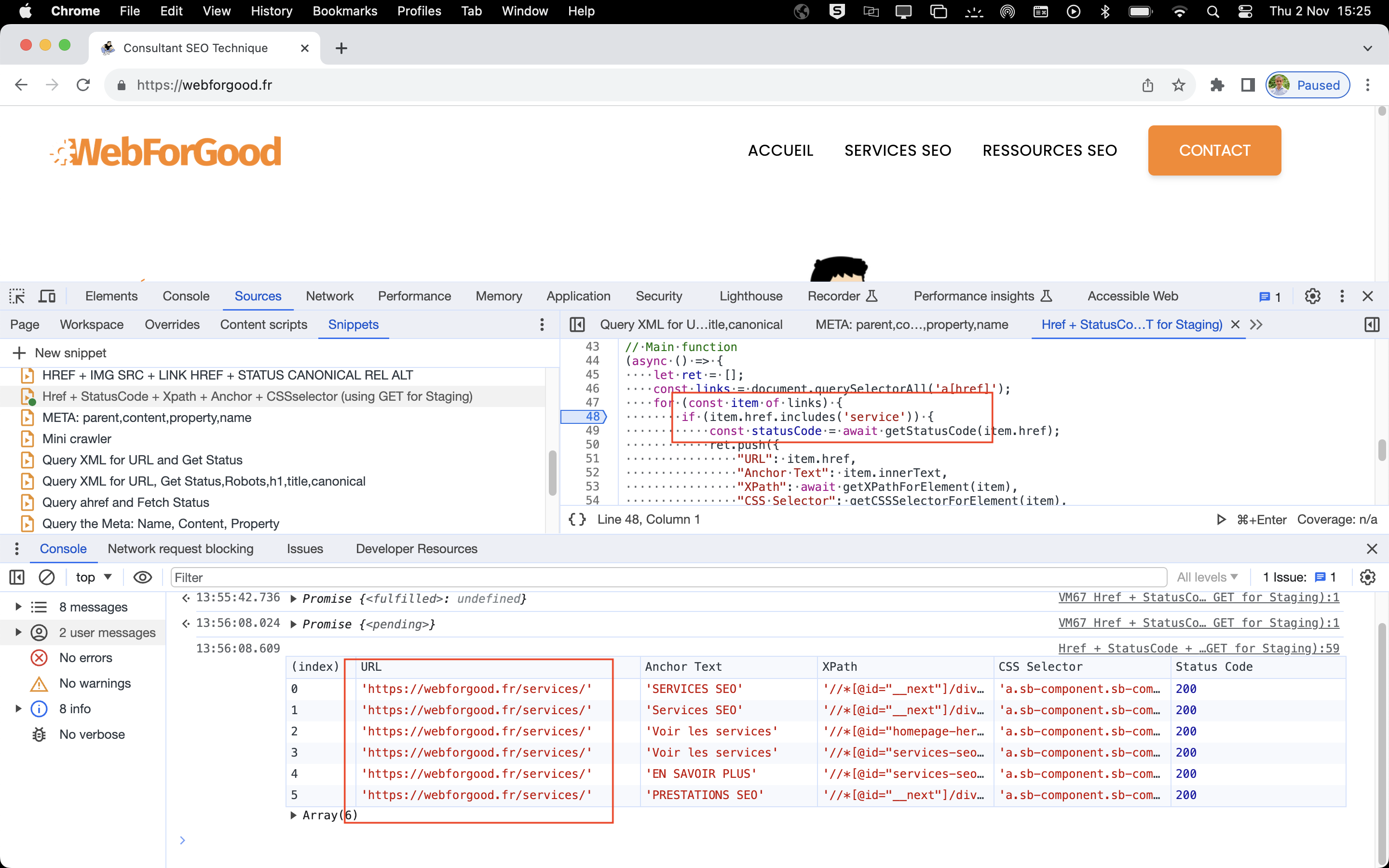
In the above example, the URL for /services/ has been fixed, I can verify its HTTP status code, anchor text, and I could look up a certain position of the element in the HTML by copying the CSS selector and pasting in the Elements tab in the browser's DevTools:
🧐 Conclusion: You can perform the same action with an extension or by crawling the page in your favourite crawler, but it will cost you some precious minutes that you could use elsewhere.
With this snippet, you find the HTTP status code of a particular URLs along with its position in the HTML and anchor text in less than a second.
Keep in mind that you get a maximum of 999 results and that the word you are looking for is case sensitive. Amazing what you can with your browser, simple and fast. Grab the code above, change the value for item.href.includes, and off you go. If you want all URLs, just change it to "/" . It can take up to 45 seconds to get the results for 190 URLs found on a page. It is still much shorter than running a crawler or an extension.
⚠️ Note: External URLs will return (or should return) a 404 status code, because of the
(which is a good thing).
ℹ️ Useful tip: You could use the value "javascript" or "void" to find uncrawlable links such as href="javascript:void(0)" - speaking of which, jump to the next snippet covering the topic.
Snippet #3: Find uncrawlable links 🕸️
You know the Lighthouse or crawler alerts 🔔 about uncrawlable links? It's painfully long to wait for Lighthouse to run in the browser, isn't it? And did you tailor your crawler to find those uncrawlable links?
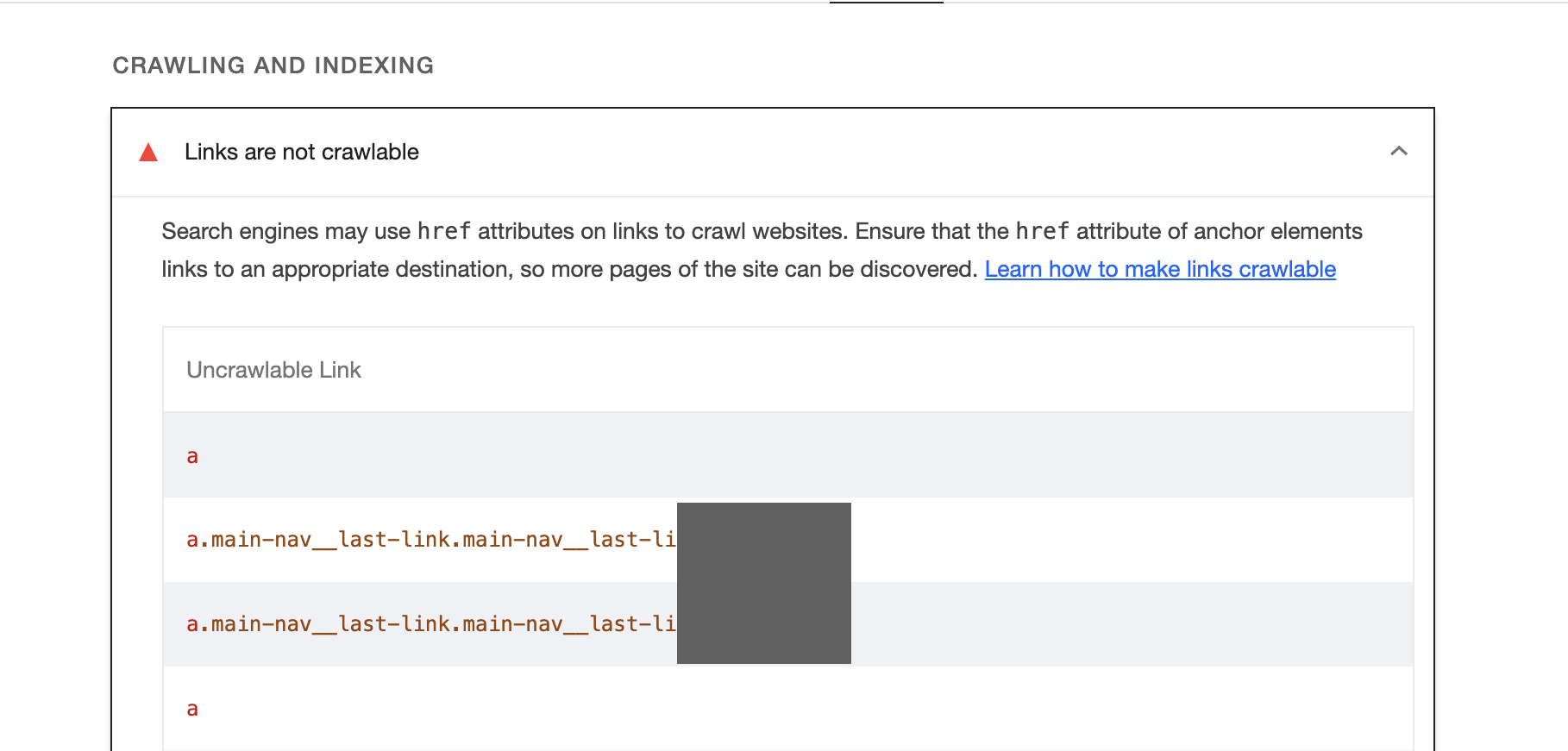
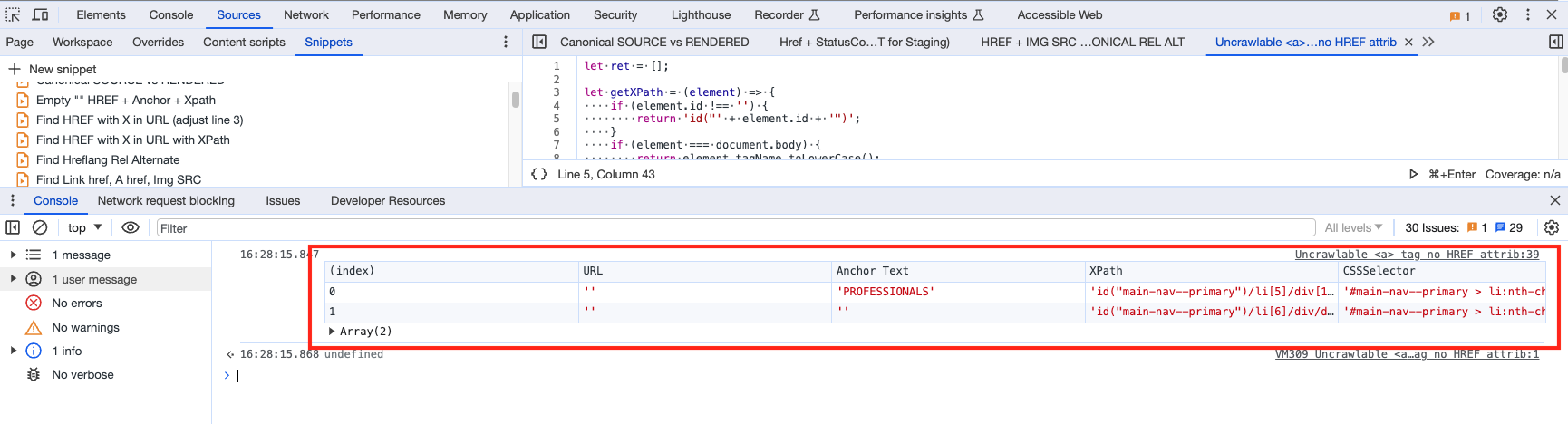
🔬 Scenario: Link best practices are such, that this is arguably one of the most underrated technical SEO optimisations and potentially a very important one. Instead of running a crawler or a lighthouse report, you could use this simple snippet to find anchor tags that do not have an href attribute.
let ret = [];
let getXPath = (element) => {
if (element.id !== '') {
return 'id("' + element.id + '")';
}
if (element === document.body) {
return element.tagName.toLowerCase();
}
var siblings = Array.from(element.parentNode.childNodes).filter(n => n.nodeType === 1 && n.tagName === element.tagName);
var position = siblings.length > 1 ? '[' + (siblings.indexOf(element) + 1) + ']' : '';
return getXPath(element.parentNode) + '/' + element.tagName.toLowerCase() + position;
};
let getCSSPath = (element) => {
let segments = [];
for (; element && element.nodeType === 1; element = element.parentNode) {
if (element.id) {
segments.unshift('#' + element.id);
break;
} else {
let position = Array.from(element.parentNode.children).indexOf(element) + 1;
position = position > 1 ? ':nth-child(' + position + ')' : '';
segments.unshift(element.tagName.toLowerCase() + position);
}
}
return segments.join(' > ');
};
document.querySelectorAll('a:not([href])').forEach(function(item) {
ret.push({
"URL": item.href,
"Anchor Text": item.innerText,
"XPath": getXPath(item),
"CSSSelector": getCSSPath(item) // Changed "CSS Path" to "CSSSelector"
});
});
console.table(ret);The result shows us an empty URL as expected, but also the anchor text and the CSS selector.
🧐 Conclusion: The above snippet uses document.querySelectorAll to find all anchor (a) tags without an href attribute, and returns the following:
The `href` attribute that will be an empty string since these elements do not have `href`.
The inner text of the element (`Anchor Text`).
The XPath of the element, calculated using the `getXPath` function.
The CSS selector path of the element, calculated using the `getCSSPath` function.
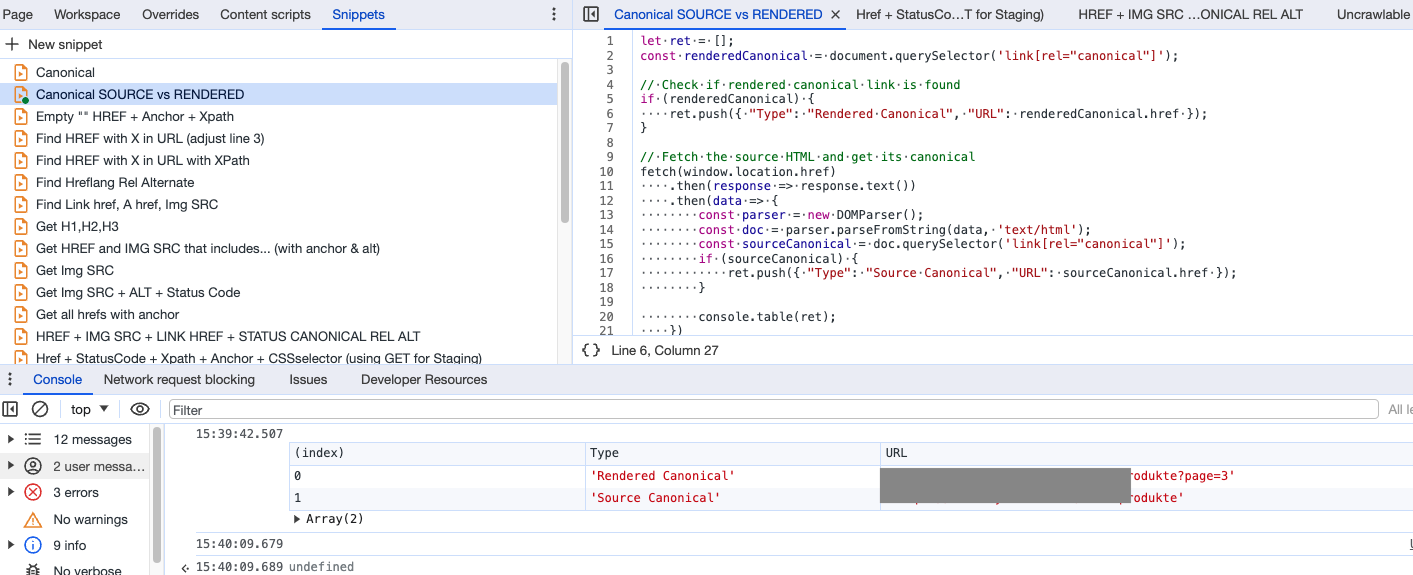
Snippet #4: Find and compare rendered HTML canonical URL vs source HTML canonical URL
🔬 Scenario: When dealing with Javascript rendering, you will find situation where the HTML is modified in the browser after receiving the server HTML.
In other words, when a browser requests a webpage, the server sends the source HTML. The browser then parses this HTML, creates the DOM, and renders the page for the viewer. Any subsequent changes made by JavaScript will alter the DOM, and thus the rendered HTML, but not the source HTML. To see the rendered HTML, you would typically use the browser's developer tools Elements tab. The source HTML can be seen in the Page tab under Sources.
Now, Google and modern search engines are sophisticated enough and we can arguably say that only the rendered HTML matters, however, why send conflicting signals when we can avoid it (especially on meta data)? Here's a snippet that I often use to check for discrepancies between rendered HTML canonical URL and the source canonical URL.
let ret = [];
const renderedCanonical = document.querySelector('link[rel="canonical"]');
// Check if rendered canonical link is found
if (renderedCanonical) {
ret.push({ "Type": "Rendered Canonical", "URL": renderedCanonical.href });
}
// Fetch the source HTML and get its canonical
fetch(window.location.href)
.then(response => response.text())
.then(data => {
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'text/html');
const sourceCanonical = doc.querySelector('link[rel="canonical"]');
if (sourceCanonical) {
ret.push({ "Type": "Source Canonical", "URL": sourceCanonical.href });
}
console.table(ret);
})
.catch(err => {
console.error("Error fetching original source:", err);
});
Snippet #5: Run a mini-crawler script on a page
🔬 Scenario: You don't have SEO extensions (or don't want / can't use them) and have no time to run a crawler for one page. Here's a mini-crawler script that you can enhance to get the most of your browser's DevTools for SEO.
//Modify LINE 77
async function getXPathForElement(element) {
let xpath = '';
for (; element && element.nodeType === 1; element = element.parentNode) {
const id = element.getAttribute('id');
if (id) {
xpath =
async function getStatusCode(url) {
try {
const response = await fetch(url, {method: 'GET'});
return response.status;
} catch (error) {
return 'Error: Unable to fetch';
}
}
(async () => {
let ret = [];
// Check and capture canonical URLs
const renderedCanonical = document.querySelector('link[rel="canonical"]');
if (renderedCanonical) {
ret.push({ "Type": "Rendered Canonical", "URL": renderedCanonical.href });
}
try {
const response = await fetch(window.location.href);
const data = await response.text();
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'text/html');
const sourceCanonical = doc.querySelector('link[rel="canonical"]');
if (sourceCanonical) {
ret.push({ "Type": "Source Canonical", "URL": sourceCanonical.href });
}
// Retrieving the H1 and H2 tags
const h1 = doc.querySelector('h1');
const h2s = doc.querySelectorAll('h2');
if (h1) ret.push({ "Type": "H1", "Content": h1.innerText });
h2s.forEach((h2, index) => {
ret.push({ "Type": `H2-${index + 1}`, "Content": h2.innerText });
});
// Retrieving meta robots, link hreflang, meta title, and meta description
const metaRobots = doc.querySelector('meta[name="robots"]');
const linkHreflangs = doc.querySelectorAll('link[rel="alternate"][hreflang]');
const metaTitle = doc.querySelector('title');
const metaDescription = doc.querySelector('meta[name="description"]');
if (metaRobots) ret.push({ "Type": "Meta Robots", "Content": metaRobots.getAttribute("content") });
linkHreflangs.forEach((link, index) => {
ret.push({ "Type": `Hreflang-${index + 1}`, "Content": link.getAttribute("hreflang") });
});
if (metaTitle) {
ret.push({ "Type": "Meta Title", "Content": metaTitle.innerText, "Character Count": metaTitle.innerText.length });
}
if (metaDescription) {
ret.push({ "Type": "Meta Description", "Content": metaDescription.getAttribute("content"), "Character Count": metaDescription.getAttribute("content").length });
}
} catch (err) {
console.error("Error fetching original source:", err);
}
// Check, capture, and display status for specified or desired hyperlinks - Modify LINE 77
const links = document.querySelectorAll('a[href]');
for (const item of links) {
if (item.href.includes('/')) {
const statusCode = await getStatusCode(item.href);
let canonical;
try {
const response = await fetch(item.href);
const data = await response.text();
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'text/html');
const linkCanonical = doc.querySelector('link[rel="canonical"]');
canonical = linkCanonical ? linkCanonical.href : 'Not found';
} catch (err) {
canonical = 'Error fetching canonical';
}
ret.push({
"URL": item.href,
"Anchor Text": item.innerText,
"XPath": await getXPathForElement(item),
"Status Code": statusCode,
"Canonical": canonical
});
}
}
console.table(ret);
})();In this snippet, we check the canonical URL, the title and meta description along with the character count, the Hn headings, the meta robots tag and the URLs found on the page along with their HTTP status code, anchor text, CSS Selector and their canonical URLs.
This gives you a fast snapshot of the page you are on. Here's a screenshot example:
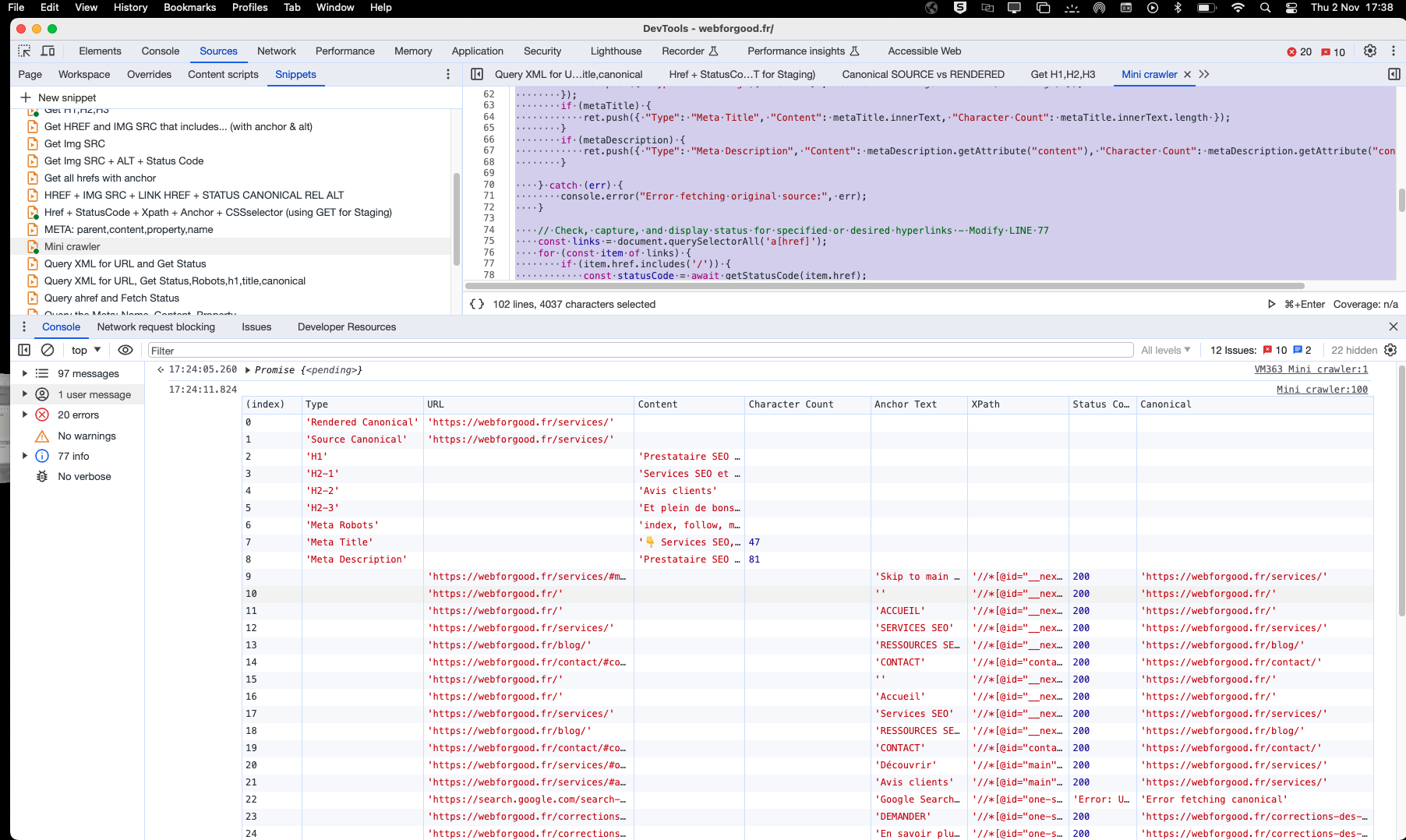
Conclusion:
You get the drill by now; the aim here is to double check of a volume of issues in a record short time, using only your browser. The cool thing with Snippets is the fact that you can save them in your browser for repeat usage, and you can tailor them for your needs at every run.
A few more snippets
Snippet #6: Get all metas found in the head
console.table(Array.from($$('meta')).map(el => ({ parent: el.parentElement.tagName, name: el.getAttribute('name'), content: el.getAttribute('content'), property: el.getAttribute('property') })), ['parent', 'name', 'content', 'property'])Snippet #7: Get the SRC attribute of the images on the page (along with their ALT text and HTTP status code)
let ret = [];
// Function to find URLs
function findImgSrc() {
document.querySelectorAll('img[src]').forEach(function(item) {
if (item.src.includes('/')) {
checkImageStatus(item.src).then(status => {
ret.push({ "Type": "Image", "URL": item.src, "Alt Text": item.alt, "Status": status });
});
}
});
}
// Function to check the status of an image URL
async function checkImageStatus(url) {
try {
const response = await fetch(url, {
method: 'HEAD', // Only get headers to make it faster
});
return response.status;
} catch (error) {
return 'Error';
}
}
// Run the function to find image sources
findImgSrc();
// Wait some time and then output the results
// Note: In a real-world application, you'd wait for all promises to resolve.
// This is just for demonstration.
setTimeout(() => {
console.table(ret);
}, 3000);Snippet #8: Get hreflang link alternate tag found on the page
let ret = [];
const canonical = document.querySelector('link[rel="canonical"]');
const hreflangs = document.querySelectorAll('link[rel="alternate"]');
// Check if canonical link is found
if (canonical) {
ret.push({ "Type": "Canonical", "URL": canonical.href, "Language": "N/A" });
}
// Check if hreflang links are found
if (hreflangs.length > 0) {
hreflangs.forEach(link => {
const lang = link.getAttribute('hreflang');
const url = link.getAttribute('href');
if (lang && url) {
ret.push({ "Type": "Hreflang", "URL": url, "Language": lang });
}
});
}
console.table(ret);Snippet #9: Get the hreflang URLs on an XML Sitemap
let ret = [];
document.querySelectorAll('link[hreflang]').forEach(function(item) {
ret.push({ "URL": item.href, "Language": item.hreflang });
});
console.table(ret);