Chrome DevTools pour le SEO dans un Environnement Clos
Dans un environment clos où le choix des extensions SEO et l'utilisation des outils de crawl est réduit, on fait recourt au DevTools Chrome ou Firefox. Après tout, le navigateur est connecté aux environnements de l'entreprise et "sert" les cookies nécessaires au bon fonctionnement de vos tests (approuvé en quelque sorte).
Ce qui suit couvre 9 extraits de code (Chrome Devtools Snippets) que je trouve très utiles, que vous pouvez adopter dans votre travail SEO au quotidien, en exploitant la puissance et simplicité des navigateurs (Chrome, Firefox) pour gagner en temps et en efficacité.
Si vous utilisez déjà l'onglet Réseau ou Éléments pour vérifier des pages du site, ou pour valider des tickets Jira, etc... vous allez apprécier ces extraits de JS et leurs résultats (tableau) affichés dans la Console.
Ce tutoriel est disponible en anglais 🇬🇧
Bienvenue dans les extraits de code Chrome !
Voici une introduction aux extraits de code dans Chrome > outils de développement (DevTools), provenant de la chaîne YouTube Chrome for Developers : (Sous-titrage en français automatisé).

Maintenant que nous avons pris connaissance des snippets (extraits), explorons un peu plus quelques unes de leurs applications pour le SEO.
Contenu :
- Extrait #1 : Vérifier les URLs d'un plan de site XML (avec leur balises canoniques, la balise meta robots, le code de statut HTTP et la directive Disallow)
- Snippet #2 : Trouver les attributs href sur une page 🧶 (avec leur code de statut et le texte de l'ancre)
- Snippet #3: Trouver les liens non-explorables 🕸️
- Snippet #4: Trouver et comparer l'URL canonique du HTML rendu avec celle du HTML source
- Snippet #5: Exécuter un script de mini-crawler sur une page
- Snippet #6: Obtenir toutes les balises meta situées dans le head
- Snippet #7: Obtenir les attributs SRC des images (ainsi que leur ALT et leur code de statut HTTP)
- Snippet #8: Obtenir les balises de lien alternatif de langue hreflang
- Snippet #9: Obtenir les URLs hreflang dans un plan de site XML
Pourquoi?
Évoluant dans un cadre d'entreprise, notre marge de manœuvre quant à l'utilisation d'outils de crawl, ainsi que les extensions, est assez restreinte pour des raisons de sécurité pour le moins.
Cela nous amène à réfléchir sur certaines tâches répétitives du quotidien: comment je vais améliorer mon output sans utiliser les extensions de Chrome / Firefox, et sans passer une éternité sur les crawlers tel que Screaming Frog, OnCrawl, SiteBulb, etc (ce qui n'est pas sans coût pour les serveurs de l'entreprise).
Si vous êtes curieux, si vous utilisez déjà les onglets Éléments, Réseau et autres dans les DevTools et que ...
... vous ne pouvez pas utiliser ou vous ne souhaitez pas utiliser des extensions de navigateur (comme on vient de le voir ci-dessus).
... et que ça ne vous dérange pas que les résultats soient affichés dans la 'Console' de votre navigateur, ce mini-guide DevTools pour le SEO est pour vous.
⚠️ NB 1: Limité à maximum 999 résultats.
⚠️ NB 2: attention à la "casse" (majuscules vs minuscules).
Extrait #1 :Vérifier les URLs d'un plan de site XML (avec leur balises canoniques, la balise meta robots, le code de statut HTTP et la directive Disallow)
🔬 Scénario : Vous travaillez sur un plan du site (XML).
Vous avez identifié que certaines pages incluses dans le plan du site ne sont pas indexables et vous souhaitez les retirer du plan du site, ou certaines pages sont exclues de l'exploration dans le fichier robots.txt et vous souhaitez les maintenir ainsi, ou vous travaillez simplement à retirer certaines pages inutiles du plan de site XML.
Quelques soient les raisons, vous avez demandé à votre équipe d'effectuer les modifications et vous souhaitez vérifier la mise en œuvre, d'abord sur un environnement de pré-prod, puis sur le serveur en direct.
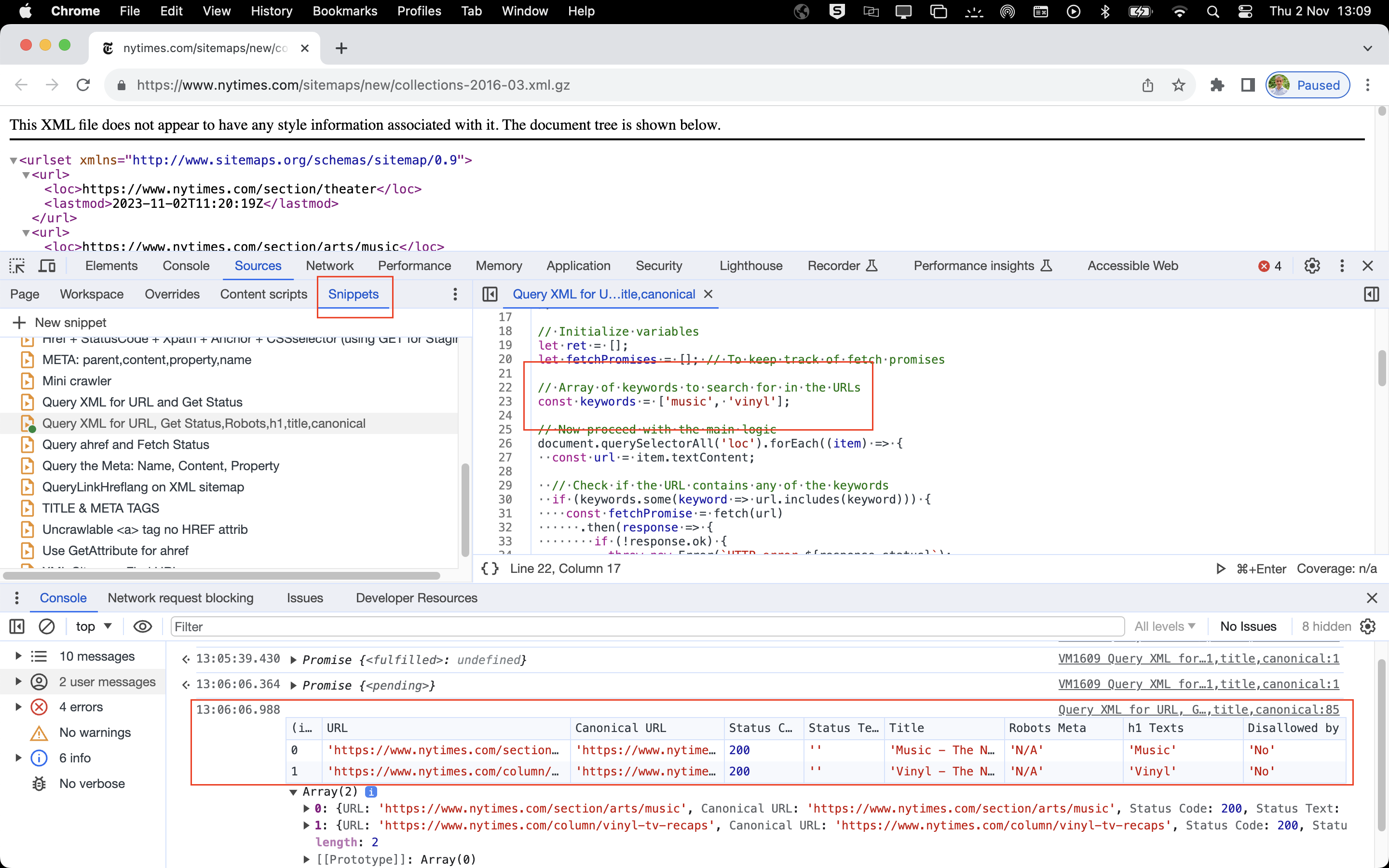
Voici un extrait de JS qui recherche les 'mots' que vous souhaitez retrouver dans les URLs, il les compare avec le fichier robots.txt, puis il vérifie leurs codes HTTP header (200, 404... par ex), il examine la présence de balises meta, et il contrôle les URLs canoniques.
// Async function to check if URL is allowed by robots.txt
const isAllowedByRobotsTxt = async (url) => {
const robotsUrl = `${new URL(url).origin}/robots.txt`;
try {
const content = await (await fetch(robotsUrl)).text();
const userAgentRules = content.split('User-agent: \*');
if (userAgentRules.length < 2) return true;
const rules = userAgentRules\[1].split('User-agent:')\[0];
const disallowedPaths = rules.split('\n')
.filter(line => line.trim().startsWith('Disallow:'))
.map(line => line.split('Disallow:')\[1].trim());
return !disallowedPaths.some(path => new URL(url).pathname.startsWith(path));
} catch (e) {
return true; // Assume allowed if there's an error fetching or parsing robots.txt
}
};
// Initialize variables
let ret = \[];
let fetchPromises = \[]; // To keep track of fetch promises
// Array of keywords to search for in the URLs
const keywords = \['terms', 'tum', '404', 'cookie'];
// Now proceed with the main logic
document.querySelectorAll('loc').forEach((item) => {
const url = item.textContent;
// Check if the URL contains any of the keywords
if (keywords.some(keyword => url.includes(keyword))) {
const fetchPromise = fetch(url)
.then(response => {
if (!response.ok) {
throw new Error(`HTTP error ${response.status}`);
}
return { response, text: response.text() };
})
.then(({ response, text }) => Promise.all(\[response, text]))
.then(async (\[response, html]) => {
const parser = new DOMParser();
const doc = parser.parseFromString(html, 'text/html');
const h1Texts = Array.from(doc.querySelectorAll('h1')).map(h1 => h1.textContent).join(', ');
// Check for robots meta tag in <head>
const metaRobots = doc.querySelector('head meta[name="robots"]');
const metaContent = metaRobots ? metaRobots.getAttribute('content') : 'N/A';
// Check for canonical URL
const canonicalLink = doc.querySelector('head link[rel="canonical"]');
const canonicalUrl = canonicalLink ? canonicalLink.getAttribute('href') : 'N/A';
// Check if the URL is allowed by robots.txt
const isAllowed = await isAllowedByRobotsTxt(url);
ret.push({
"URL": url,
"Canonical URL": canonicalUrl,
"Status Code": response.status,
"Status Text": response.statusText,
"Title": doc.title,
"Robots Meta": metaContent,
"h1 Texts": h1Texts,
"Disallowed by Robots.txt": isAllowed ? "No" : "Yes"
});
})
.catch(error => {
ret.push({
"URL": url,
"Canonical URL": "N/A",
"Status Code": "Error",
"Status Text": error.message,
"Title": "N/A",
"Robots Meta": "N/A",
"h1 Texts": "N/A",
"Disallowed by Robots.txt": "Check Failed"
});
});
fetchPromises.push(fetchPromise);
}
});
// Wait for all fetch calls to complete and then print the table
Promise.all(fetchPromises).then(() => {
console.table(ret);
});Dans cet exemple, on demande au navigateur de vérifier s'il trouve des URLs sur le plan du site XML qui contiennent les mots 'terms' ou '404' ou 'tum' ou 'cookie'. Le CMS est en train d'inclure la page exemple.fr/404-not-found dans le plan du site, ce qui est ... indésirable.
Un petit copier / coller dans un extrait de votre navigateur (Chrome ou Firefox), avant de visiter un plan de site XML pour en vérifier quelques URLs, pourra vous économiser plusieurs minutes de crawl.
Voici un exemple :
ℹ️ Astuce :
Voici un marque-page pour aller rapidement vers les plans de site XML des sites fréquemment consultés.
Il s'agit d'un petit morceau de JavaScript qui est enregistré comme un signet dans le navigateur. Le JavaScript exécute un script - très semblable à une extension - lorsque vous cliquez dessus, sans envoyer des infos aux tiers.
Dans ce cas, le marque-page ci-dessous ouvrira le plan de site du site web actuel sur lequel vous êtes, à condition que la structure de l'URL soit 'domaine.com/sitemap.xml'. Vous pouvez évidemment l'ajuster selon la structure du site étudié.
Lorsqu'ils sont combinés,
window.location.origin + '/sitemap.xml'il génère une URL qui pointe vers le plan de site de la page web sur lequel vous êtes actuellement. Si l'emplacement du plan de site est, disons, sous le dossier /niveau-2/, alors vous pourriez l'ajuster pour qu'il devienne
window.location.origin + '/niveau-2/sitemap.xml'.
javascript:(function(){window.open(window.location.origin + '/sitemap.xml');})();Snippet #2 : Trouver les attributs href sur une page 🧶 (avec leur code de statut et le texte de l'ancre)
🔬 Exemple d'usage : L'une des tâches récurrentes du quotidien, c'est la recherche et la vérification des liens internes - qu'ils soient brisés ou autres.
Imaginez, vous avez demandé à ce que certaines URLs brisées soient corrigées par vos dev, et maintenant vous devez vérifier qu'elles le sont bel et bien.
Vous avez généralement besoin de l'emplacement du lien (Xpath ou CSSselector), du code HTTP de l'URL cible et du texte d'ancrage.
// Function to get XPath for an element
async function getXPathForElement(element) {
let xpath = '';
for (; element && element.nodeType === 1; element = element.parentNode) {
const id = element.getAttribute('id');
if (id) {
xpath =
// Function to get CSS selector for an element
function getCSSSelectorForElement(element) {
if (element.id) {
return
// Function to get status code for a URL
async function getStatusCode(url) {
try {
const response = await fetch(url, {
method: 'GET',
credentials: 'include' // Include credentials like cookies in the request
});
return response.status;
} catch (error) {
return 'Error: Unable to fetch';
}
}
// Main function
(async () => {
let ret = [];
const links = document.querySelectorAll('a[href]');
for (const item of links) {
if (item.href.includes('service')) {
const statusCode = await getStatusCode(item.href);
ret.push({
"URL": item.href,
"Anchor Text": item.innerText,
"XPath": await getXPathForElement(item),
"CSS Selector": getCSSSelectorForElement(item),
"Status Code": statusCode
});
}
}
console.table(ret);
})();Avec cet exemple, je recherche l'attribut href qui inclut le mot 'service'.
Au lieu de lancer un nouveau crawl, et puisque je sais en amont ce que je recherche, je pourrais exécuter ce fragment de code - même dans des environnements de pré-prod - pour rechercher ce que je pense avoir été corrigé par les devs, et obtenir le résultat dans la console du navigateur, le tout en moins d'une seconde.
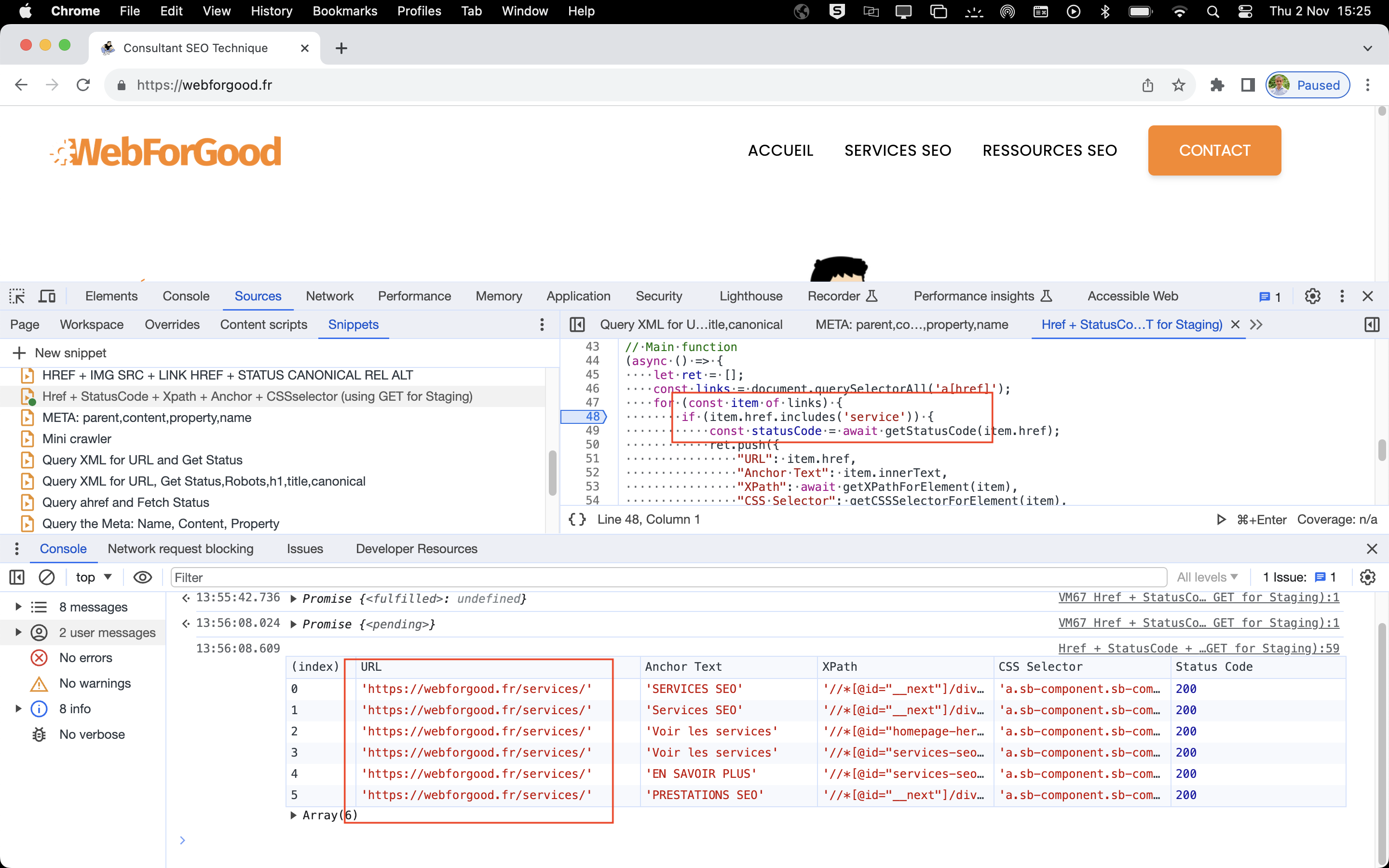
🧐 Conclusion: Vous pouvez effectuer la même action avec une extension ou en crawlant la page avec votre outil de crawl préféré, mais cela vous coûterait quelques précieuses minutes.
Avec ce fragment de code, vous trouvez le statut HTTP d'URLs ainsi que leur position dans le HTML et le texte d'ancrage en moins d'une seconde.
Vous obtenez un maximum de 999 résultats, sans oublier que le 'mot' que vous recherchez est sensible à la casse (majuscule/miniscule).
C'est incroyable ce que vous pouvez faire avec votre navigateur, simple et rapide.
Prenez le code ci-dessus, changez la valeur pour item.href.includes, et c'est parti. Si vous voulez toutes les URLs, changez la valeur en "/". Cela peut prendre jusqu'à 45 secondes pour obtenir les résultats pour 190 URLs trouvés sur une page. Ça bien plus rapide qu'un crawler.
⚠️ A noter : Les URLs externes auront le statut HTTP 404, à cause de la politique de sécurité CORS mise en place par les dev, ce qui est une bonne chose en soi.
ℹ️ Astuce : Vous pourriez utiliser la valeur "javascript" ou "void" pour trouver des liens non indexables tels que href="javascript:void(0)", place à l'extrait suivant.
Snippet #3: Trouver les liens non-explorables 🕸️
L'analyse de chargement de page Lighthouse est particulièrement utile pour trouver les problèmes de liens non-explorables. Mais l'outil est assez lent, et donc voici un extrait qui nous facilitera la tâche.
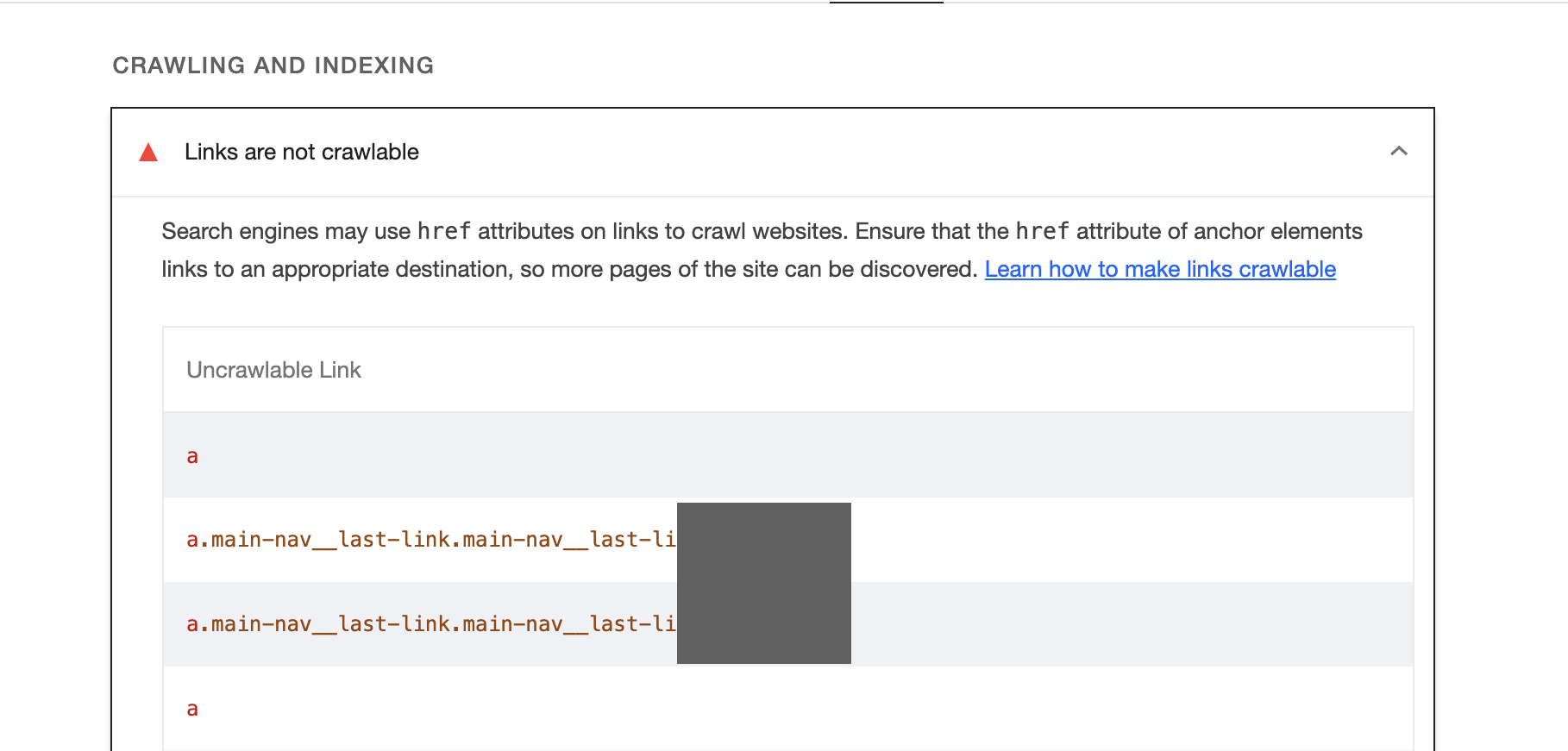
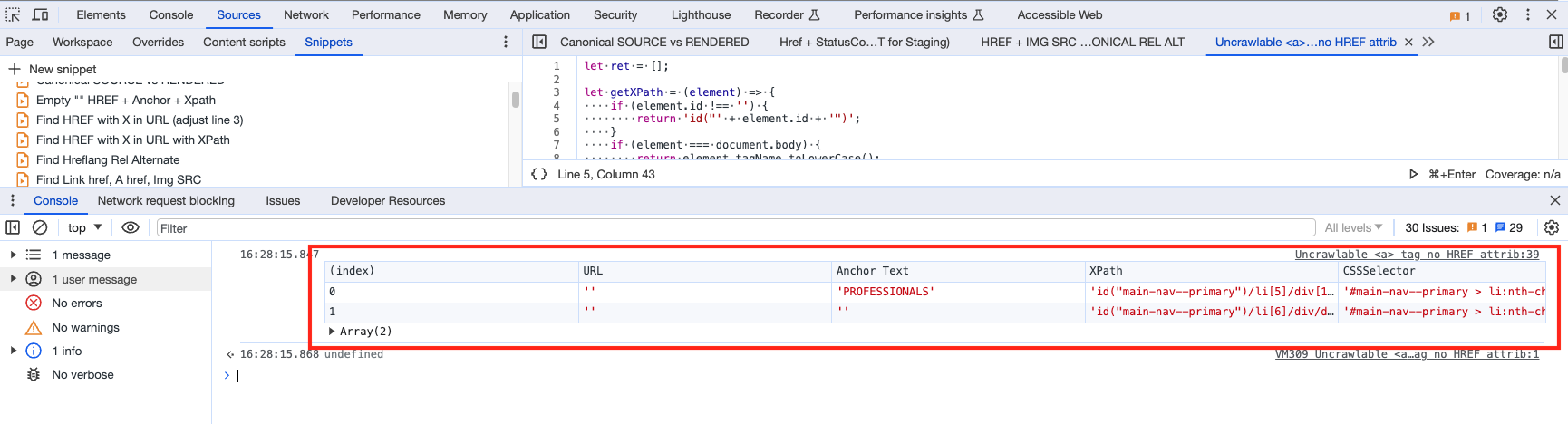
🔬 Exemple concret : Les moteurs de recherche peuvent utiliser les attributs href des liens pour explorer les sites Web. En leur offrant des liens non optimisés, on risque un gaspillage au niveau du crawl.
Au lieu de faire tourner votre Lighthouse, voici un extrait rapide pour votre DevTools:
let ret = [];
let getXPath = (element) => {
if (element.id !== '') {
return 'id("' + element.id + '")';
}
if (element === document.body) {
return element.tagName.toLowerCase();
}
var siblings = Array.from(element.parentNode.childNodes).filter(n => n.nodeType === 1 && n.tagName === element.tagName);
var position = siblings.length > 1 ? '[' + (siblings.indexOf(element) + 1) + ']' : '';
return getXPath(element.parentNode) + '/' + element.tagName.toLowerCase() + position;
};
let getCSSPath = (element) => {
let segments = [];
for (; element && element.nodeType === 1; element = element.parentNode) {
if (element.id) {
segments.unshift('#' + element.id);
break;
} else {
let position = Array.from(element.parentNode.children).indexOf(element) + 1;
position = position > 1 ? ':nth-child(' + position + ')' : '';
segments.unshift(element.tagName.toLowerCase() + position);
}
}
return segments.join(' > ');
};
document.querySelectorAll('a:not([href])').forEach(function(item) {
ret.push({
"URL": item.href,
"Anchor Text": item.innerText,
"XPath": getXPath(item),
"CSSSelector": getCSSPath(item) // Changed "CSS Path" to "CSSSelector"
});
});
console.table(ret);🧐 Conclusion: Le fragment de code ci-dessus utilise document.querySelectorAll pour trouver tous les éléments d'ancre (a) sans attribut href, et retourne les éléments suivants :
L'attribut
hrefqui sera une chaîne vide puisque ces éléments n'ont pas dehref.Le texte interne de l'élément (
Texte d'ancrage).Le XPath de l'élément, calculé en utilisant la fonction
getXPath.Le chemin du sélecteur CSS de l'élément, calculé en utilisant la fonction
getCSSPath.
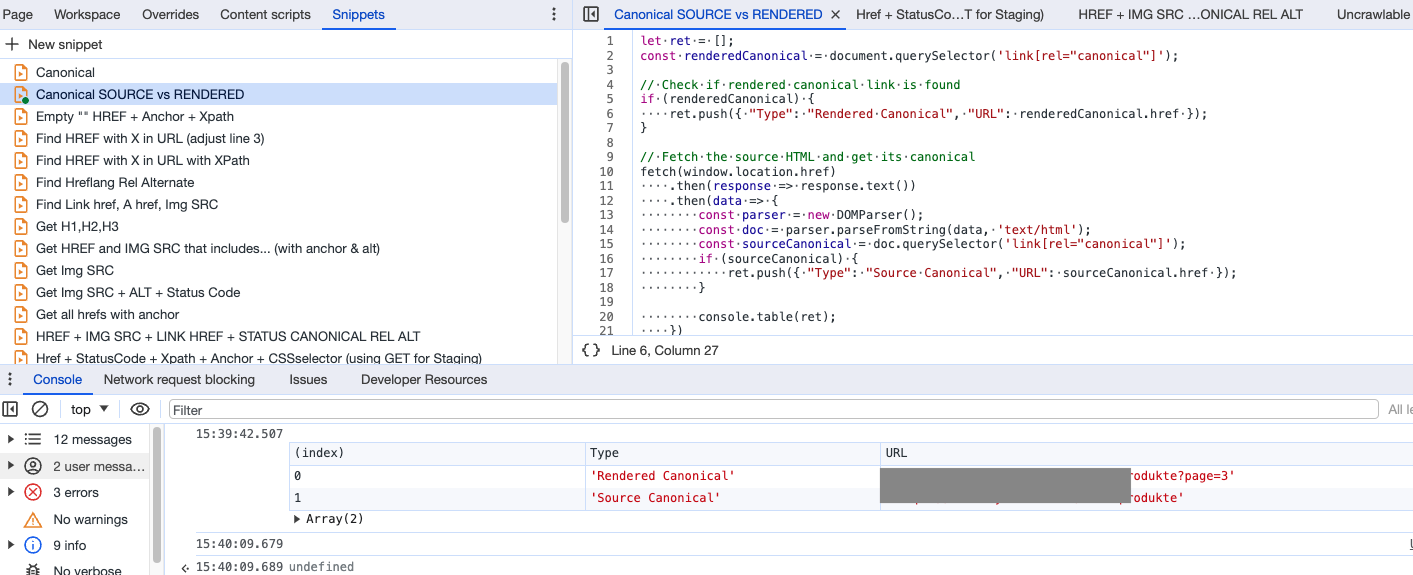
Snippet #4: Trouver et comparer l'URL canonique du HTML rendu avec celle du HTML source
🔬 Exemple pratique :
Lorsque vous êtes confronté au rendu Javascript, vous trouverez des situations où le HTML est modifié dans le navigateur après avoir reçu le HTML du serveur.
En d'autres termes, lorsqu'un navigateur demande une page web, le serveur envoie l'HTML source. Le navigateur analyse cet HTML, crée le DOM et affiche la page pour l'utilisateur. Toute modification ultérieure apportée par JavaScript va modifier le DOM et donc le HTML rendu, mais pas l'HTML source.
Pour voir l'HTML rendu, vous utiliseriez généralement l'onglet Éléments des outils de développement du navigateur. L'HTML source se trouve dans l'onglet Sources (Page).
De nos jours, Google et les moteurs de recherche modernes sont suffisamment sophistiqués pour "comprendre" le DOM et l'HTML rendu, cependant, pourquoi envoyer des signaux contradictoires alors que nous pouvons les éviter ? Voici un fragment de code que j'utilise pour vérifier les écarts entre l'URL canonique du HTML rendu et l'URL canonique source.
let ret = [];
const renderedCanonical = document.querySelector('link[rel="canonical"]');
// Check if rendered canonical link is found
if (renderedCanonical) {
ret.push({ "Type": "Rendered Canonical", "URL": renderedCanonical.href });
}
// Fetch the source HTML and get its canonical
fetch(window.location.href)
.then(response => response.text())
.then(data => {
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'text/html');
const sourceCanonical = doc.querySelector('link[rel="canonical"]');
if (sourceCanonical) {
ret.push({ "Type": "Source Canonical", "URL": sourceCanonical.href });
}
console.table(ret);
})
.catch(err => {
console.error("Error fetching original source:", err);
});
Snippet #5: Exécuter un script de mini-crawler sur une page
🔬 Exemple d'usage :
Vous ne pouvez pas utiliser d'extensions SEO et vous n'avez pas le temps de lancer un crawler pour une seule page. Voici un script de mini-crawler que vous pouvez améliorer pour tirer le meilleur parti des outils de développement de votre navigateur pour le SEO.
//Modify LINE 77
async function getXPathForElement(element) {
let xpath = '';
for (; element && element.nodeType === 1; element = element.parentNode) {
const id = element.getAttribute('id');
if (id) {
xpath =
async function getStatusCode(url) {
try {
const response = await fetch(url, {method: 'GET'});
return response.status;
} catch (error) {
return 'Error: Unable to fetch';
}
}
(async () => {
let ret = [];
// Check and capture canonical URLs
const renderedCanonical = document.querySelector('link[rel="canonical"]');
if (renderedCanonical) {
ret.push({ "Type": "Rendered Canonical", "URL": renderedCanonical.href });
}
try {
const response = await fetch(window.location.href);
const data = await response.text();
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'text/html');
const sourceCanonical = doc.querySelector('link[rel="canonical"]');
if (sourceCanonical) {
ret.push({ "Type": "Source Canonical", "URL": sourceCanonical.href });
}
// Retrieving the H1 and H2 tags
const h1 = doc.querySelector('h1');
const h2s = doc.querySelectorAll('h2');
if (h1) ret.push({ "Type": "H1", "Content": h1.innerText });
h2s.forEach((h2, index) => {
ret.push({ "Type": `H2-${index + 1}`, "Content": h2.innerText });
});
// Retrieving meta robots, link hreflang, meta title, and meta description
const metaRobots = doc.querySelector('meta[name="robots"]');
const linkHreflangs = doc.querySelectorAll('link[rel="alternate"][hreflang]');
const metaTitle = doc.querySelector('title');
const metaDescription = doc.querySelector('meta[name="description"]');
if (metaRobots) ret.push({ "Type": "Meta Robots", "Content": metaRobots.getAttribute("content") });
linkHreflangs.forEach((link, index) => {
ret.push({ "Type": `Hreflang-${index + 1}`, "Content": link.getAttribute("hreflang") });
});
if (metaTitle) {
ret.push({ "Type": "Meta Title", "Content": metaTitle.innerText, "Character Count": metaTitle.innerText.length });
}
if (metaDescription) {
ret.push({ "Type": "Meta Description", "Content": metaDescription.getAttribute("content"), "Character Count": metaDescription.getAttribute("content").length });
}
} catch (err) {
console.error("Error fetching original source:", err);
}
// Check, capture, and display status for specified or desired hyperlinks - Modify LINE 77
const links = document.querySelectorAll('a[href]');
for (const item of links) {
if (item.href.includes('/')) {
const statusCode = await getStatusCode(item.href);
let canonical;
try {
const response = await fetch(item.href);
const data = await response.text();
const parser = new DOMParser();
const doc = parser.parseFromString(data, 'text/html');
const linkCanonical = doc.querySelector('link[rel="canonical"]');
canonical = linkCanonical ? linkCanonical.href : 'Not found';
} catch (err) {
canonical = 'Error fetching canonical';
}
ret.push({
"URL": item.href,
"Anchor Text": item.innerText,
"XPath": await getXPathForElement(item),
"Status Code": statusCode,
"Canonical": canonical
});
}
}
console.table(ret);
})();Dans ce fragment de code, nous vérifions l'URL canonique, le titre et la méta-description ainsi que le nombre de caractères, les titres Hn, la balise méta robots et les URLs trouvées sur la page avec leur code de statut HTTP, leur texte d'ancrage, leur sélecteur CSS et leurs URL canoniques. Cela vous donne un aperçu rapide de la page sur laquelle vous êtes. Voici un exemple de capture d'écran :
Conclusion :
Vous avez compris le principe; l'objectif est de vérifier un volume de problèmes en un temps record, en utilisant rien que le navigateur Chrome ou Firefox. L'atout des fragments de code, c'est que vous pouvez les sauvegarder dans votre navigateur pour les utiliser à volonté, et vous pouvez les adapter à vos besoins à chaque exécution.
Pour aller un peu plus loin 👇
Snippet #6: Obtenir toutes les balises meta situées dans le <head>
console.table(Array.from($$('meta')).map(el => ({ parent: el.parentElement.tagName, name: el.getAttribute('name'), content: el.getAttribute('content'), property: el.getAttribute('property') })), ['parent', 'name', 'content', 'property'])Snippet #7: Obtenir les attributs SRC des images (ainsi que leur ALT et leur code de statut HTTP)
let ret = [];
// Function to find URLs
function findImgSrc() {
document.querySelectorAll('img[src]').forEach(function(item) {
if (item.src.includes('/')) {
checkImageStatus(item.src).then(status => {
ret.push({ "Type": "Image", "URL": item.src, "Alt Text": item.alt, "Status": status });
});
}
});
}
// Function to check the status of an image URL
async function checkImageStatus(url) {
try {
const response = await fetch(url, {
method: 'HEAD', // Only get headers to make it faster
});
return response.status;
} catch (error) {
return 'Error';
}
}
// Run the function to find image sources
findImgSrc();
// Wait some time and then output the results
// Note: In a real-world application, you'd wait for all promises to resolve.
// This is just for demonstration.
setTimeout(() => {
console.table(ret);
}, 3000);Snippet #8: Obtenir les balises de lien alternatif de langue hreflang
let ret = [];
const canonical = document.querySelector('link[rel="canonical"]');
const hreflangs = document.querySelectorAll('link[rel="alternate"]');
// Check if canonical link is found
if (canonical) {
ret.push({ "Type": "Canonical", "URL": canonical.href, "Language": "N/A" });
}
// Check if hreflang links are found
if (hreflangs.length > 0) {
hreflangs.forEach(link => {
const lang = link.getAttribute('hreflang');
const url = link.getAttribute('href');
if (lang && url) {
ret.push({ "Type": "Hreflang", "URL": url, "Language": lang });
}
});
}
console.table(ret);Snippet #9: Obtenir les URLs hreflang dans un plan de site XML
let ret = [];
document.querySelectorAll('link[hreflang]').forEach(function(item) {
ret.push({ "URL": item.href, "Language": item.hreflang });
});
console.table(ret);